So the JDK 21 came out, we already had some insight into how the virtual threads looked like earlier with the preview flag. However with a proper release now it is more accessible and I encourage everyone who can to upgrade to this version.
The version consists of a lot of different features such as:
- Sequenced Collections (JEP 431)
- Generational ZGC (JEP 439)
- Record Patterns (JEP 440)
- Pattern Matching for switch (JEP 441)
- Virtual Threads (JEP 444)
- Key Encapsulation Mechanism API (JEP 452)
And much more that is currently in preview, like unnamed classes which is similar to what Kotlin does. I might check that out for a new article another time. Exciting times!
Introduction
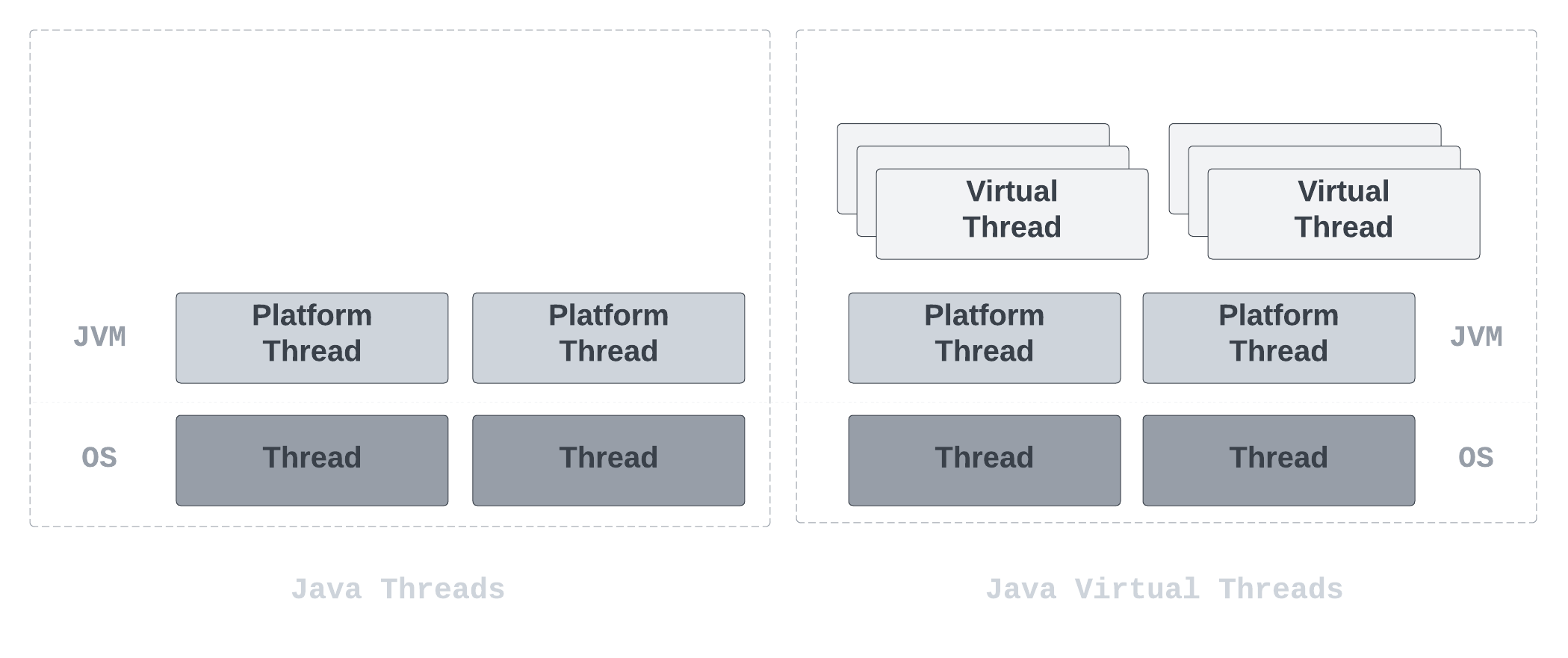
Virtual threads are lightweight threads that are cheap to create and almost infinitely plentiful. That means that they are an implementation of threads that are provided by the JDK rather than the operating system (OS).
In previous versions, threads were limited due to the fact that JDK implemented a wrapper around the operating system (OS) threads aka platform threads. So the cost of using threads was high, so we could not have too many of them.
In this article we are going to discuss what virtual threads is all about, as well as implementing platform threads and virtual threads and to compare performance between the two.
We are also going to take a look at how the scheduling works, how we now can take advantage of thread-per-request strategy once again but without the higher costs it can bring, thread pools and why you should not use it with virtual threads, memory use and interaction with garbage collector and lastly thread-local variables.
Virtual threads vs. platform threads
So what are virtual threads really and how do they differ from platform threads?
As mentioned in the introduction, platform threads act as a wrapper around the operating system (OS) threads. The JDK's virtual thread scheduler assigns the virtual thread for execution on a platform thread by mounting the virtual thread on a platform thread. In other words, the platform thread is basically the carrier of the virtual thread.
Virtual threads are not by any mean faster threads. They do not run any code faster than platform threads. They do however provide scale (higher throughput) but not speed (lower latency).
Virtual threads can significantly improve application throughput when:
- The number of concurrent tasks is high
- The workload is not CPU-bound. Having more threads than processor cores cannot improve throughput in that case.
Implementation
We will implement a task-processing system using platform threads to establish a performance baseline. Afterwards, we will create an equivalent system using virtual threads and compare the throughput of both implementations to evaluate the benefits of virtual threads.
We start off by creating the Buffer class which represents a shared buffer that facilitates communication between producers and consumers. Producers add tasks to the buffer, and consumers retrieve and process these tasks. The class ensures thread safety and efficient coordination among threads.
public class Buffer {
private LinkedList<String> data;
private int capacity;
public Buffer(int capacity) {
this.data = new LinkedList<>();
this.capacity = capacity;
}
public synchronized void produce(String task, String producerName) {
while (data.size() >= capacity) {
try {
wait();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
data.add(task);
System.out.println(producerName + " produced " + task);
notifyAll();
}
public synchronized String consume(String consumerName) {
while (data.isEmpty()) {
try {
System.out.println(consumerName + " is waiting for tasks.");
wait();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
String task = data.removeFirst();
System.out.println(consumerName + " consumed " + task);
notifyAll();
return task;
}
}
Here we have the constructor that initializes a Buffer instance with a defined capacity:
public Buffer(int capacity) {
this.data = new LinkedList<>();
this.capacity = capacity;
}
In the produce method, we ensure thread-safe access to a shared buffer by employing synchronization. First, we check if the buffer has reached its capacity to prevent overfilling. If the buffer is full, the producer thread enters a waiting state to allow other threads to run.
Exception handling is used to address potential interruptions during this wait. Once the waiting period concludes, the producer adds the new task to the buffer and logs a message indicating successful task production. A notification is sent to awaken other waiting threads, such as consumers, signalling the availability of new tasks.
public synchronized void produce(String task, String producerName) {
while (data.size() >= capacity) {
try {
wait();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
data.add(task);
System.out.println(producerName + " produced " + task);
notifyAll();
}
In the consume method, we establish synchronized access to a shared buffer to ensure thread safety. This method is designed for consumers to retrieve and process tasks from the buffer in a coordinated manner. Initially, the method checks if the buffer is empty, which prompts the consumer thread to enter a waiting state while displaying a message indicating that it's waiting for tasks.
Exception handling is employed to handle any potential interruptions during this waiting period. When tasks become available in the buffer, the consumer retrieves the next task, logs a message indicating successful consumption, and then notifies other threads (producers and consumers) about the buffer state change.
public synchronized String consume(String consumerName) {
while (data.isEmpty()) {
try {
System.out.println(consumerName + " is waiting for tasks.");
wait();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
String task = data.removeFirst();
System.out.println(consumerName + " consumed " + task);
notifyAll();
return task;
}
Let's create our Producer and Consumer class that implements the Runnable interface:
public class Producer implements Runnable {
private Buffer buffer;
private String name;
private int numTasksToProduce;
public Producer(Buffer buffer, String name, int numTasksToProduce) {
this.buffer = buffer;
this.name = name;
this.numTasksToProduce = numTasksToProduce;
}
@Override
public void run() {
for (int i = 1; i <= numTasksToProduce; i++) {
buffer.produce("task " + i, name);
}
}
}
public class Consumer implements Runnable {
private Buffer buffer;
private String name;
private int numTasksToConsume;
public Consumer(Buffer buffer, String name, int numTasksToConsume) {
this.buffer = buffer;
this.name = name;
this.numTasksToConsume = numTasksToConsume;
}
@Override
public void run() {
int tasksConsumed = 0;
while (tasksConsumed < numTasksToConsume) {
buffer.consume(name);
tasksConsumed++;
}
}
}
Within this method of the Consumer class, a consumer aims to consume a predefined number of tasks. It maintains a count of the tasks consumed. In each iteration of the loop, the consumer calls the consume method on the shared Buffer object, passing its name as a parameter.
@Override
public void run() {
int tasksConsumed = 0;
while (tasksConsumed < numTasksToConsume) {
buffer.consume(name);
tasksConsumed++;
}
}
Platform threads
Now let's create the PlatformThreads class:
public class PlatformThreads {
public static void main(String[] args) {
int numProducers = 1_000;
int numConsumers = 1_000;
int totalTasks = numProducers * 100;
Buffer buffer = new Buffer(totalTasks);
long startTime = System.nanoTime();
Thread[] producerThreads = new Thread[numProducers];
Thread[] consumerThreads = new Thread[numConsumers];
for (int i = 0; i < numProducers; i++) {
producerThreads[i] = new Thread(new Producer(buffer, "Producer " + (i + 1), totalTasks / numProducers));
producerThreads[i].start();
}
for (int i = 0; i < numConsumers; i++) {
consumerThreads[i] = new Thread(new Consumer(buffer, "Consumer " + (i + 1), totalTasks / numConsumers));
consumerThreads[i].start();
}
try {
for (int i = 0; i < numProducers; i++) {
producerThreads[i].join();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int i = 0; i < numConsumers; i++) {
consumerThreads[i].interrupt();
}
try {
for (int i = 0; i < numConsumers; i++) {
consumerThreads[i].join();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
long endTime = System.nanoTime();
double elapsedTimeSeconds = (endTime - startTime) / 1e9;
System.out.println("Performance Metrics:");
System.out.println("Elapsed Time: " + elapsedTimeSeconds + " seconds");
System.out.println("Total Tasks Processed: " + totalTasks);
System.out.println("Throughput (Tasks/Second): " + totalTasks / elapsedTimeSeconds);
}
}
Virtual threads
Now let's create the VirtualThreads class. This will basically be very similar to the PlatformThreads class but with some small modifications:
public class VirtualThreads {
public static void main(String[] args) {
int numProducers = 1_000;
int numConsumers = 1_000;
int totalTasks = numProducers * 100;
Buffer buffer = new Buffer(totalTasks);
long startTime = System.nanoTime();
Thread[] producerThreads = new Thread[numProducers];
Thread[] consumerThreads = new Thread[numConsumers];
for (int i = 0; i < numProducers; i++) {
Runnable producerTask = new Producer(buffer, "Producer " + (i + 1), totalTasks / numProducers);
producerThreads[i] = Thread.ofVirtual().start(producerTask);
}
for (int i = 0; i < numConsumers; i++) {
Runnable consumerTask = new Consumer(buffer, "Consumer " + (i + 1), totalTasks / numConsumers);
consumerThreads[i] = Thread.ofVirtual().start(consumerTask);
}
try {
for (int i = 0; i < numProducers; i++) {
producerThreads[i].join();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int i = 0; i < numConsumers; i++) {
consumerThreads[i].interrupt();
}
try {
for (int i = 0; i < numConsumers; i++) {
consumerThreads[i].join();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
long endTime = System.nanoTime();
double elapsedTimeSeconds = (endTime - startTime) / 1e9;
System.out.println("Performance Metrics:");
System.out.println("Elapsed Time: " + elapsedTimeSeconds + " seconds");
System.out.println("Total Tasks Processed: " + totalTasks);
System.out.println("Throughput (Tasks/Second): " + totalTasks / elapsedTimeSeconds);
}
}
Here, we are initializing a shared Buffer instance with a specified totalTasks capacity. The buffer acts as a data structure that facilitates the communication and coordination between producer and consumer threads. This shared buffer will allow producers to produce tasks, consumers to consume them, and ensure that the overall processing runs smoothly.
Buffer buffer = new Buffer(totalTasks);
In this section, we are creating virtual threads for producers. For each producer, a new Producer instance is created, and a virtual thread is started to execute its task. The producer threads are named based on their index and use the totalTasks value to distribute the workload among the producers evenly. This approach takes advantage of virtual threads, which are more lightweight than traditional platform threads and can efficiently handle concurrent tasks.
for (int i = 0; i < numProducers; i++) {
Runnable producerTask = new Producer(buffer, "Producer " + (i + 1), totalTasks / numProducers);
producerThreads[i] = Thread.ofVirtual().start(producerTask);
}
In this code snippet, we are waiting for all producer threads to complete their tasks by using the join method. If any interruption occurs during this waiting period, it will be caught and printed as an exception. This part of the code ensures that all producers finish their work before moving on to the next steps of the program.
try {
for (int i = 0; i < numProducers; i++) {
producerThreads[i].join();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
Here, we are first interrupting all consumer threads, which means we're signalling them to stop. Afterwards, we wait for all consumer threads to finish their work using the join method. If any interruption occurs during this waiting period, it will be caught and printed as an exception. This part of the code ensures that all consumers have completed their tasks before proceeding with the rest of the program.
for (int i = 0; i < numConsumers; i++) {
consumerThreads[i].interrupt();
}
try {
for (int i = 0; i < numConsumers; i++) {
consumerThreads[i].join();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
Performance results
As you clearly can see, virtual threads are the winner here for running 100,000 or 200,000 tasks with throughput more than double than for platform threads.
| Performance Metrics | Elapsed Time (seconds) | Total Tasks Processed | Throughput (Tasks/Second) |
|---|---|---|---|
| Virtual Threads | 0.465984125 | 100,000 | 214,599.5853399512 |
| 0.780132208 | 200,000 | 256,366.80289451656 | |
| Platform Threads | 1.068746208 | 100,000 | 93,567.5834463405 |
| 2.700846541 | 200,000 | 74,050.85663473095 |
Scheduling virtual threads
Using virtual threads means that we will not create platform threads ourselves so we need to understand how a virtual thread gets scheduled to a platform thread to do its work.
For platform threads, which are the wrapper around operating system (OS) threads, JDK relies on the scheduler of the OS. In contrast to virtual threads, the JDK has its own scheduler. Instead of assigning virtual threads to the processor directly, the JDK's scheduler assigns virtual threads to the platform threads. Then the platform threads are scheduled by the operating system (OS) as usual.
The JDK's virtual thread scheduler is basically a work-stealing ForkJoinPool that is operating in FIFO (first-in-first-out) mode.
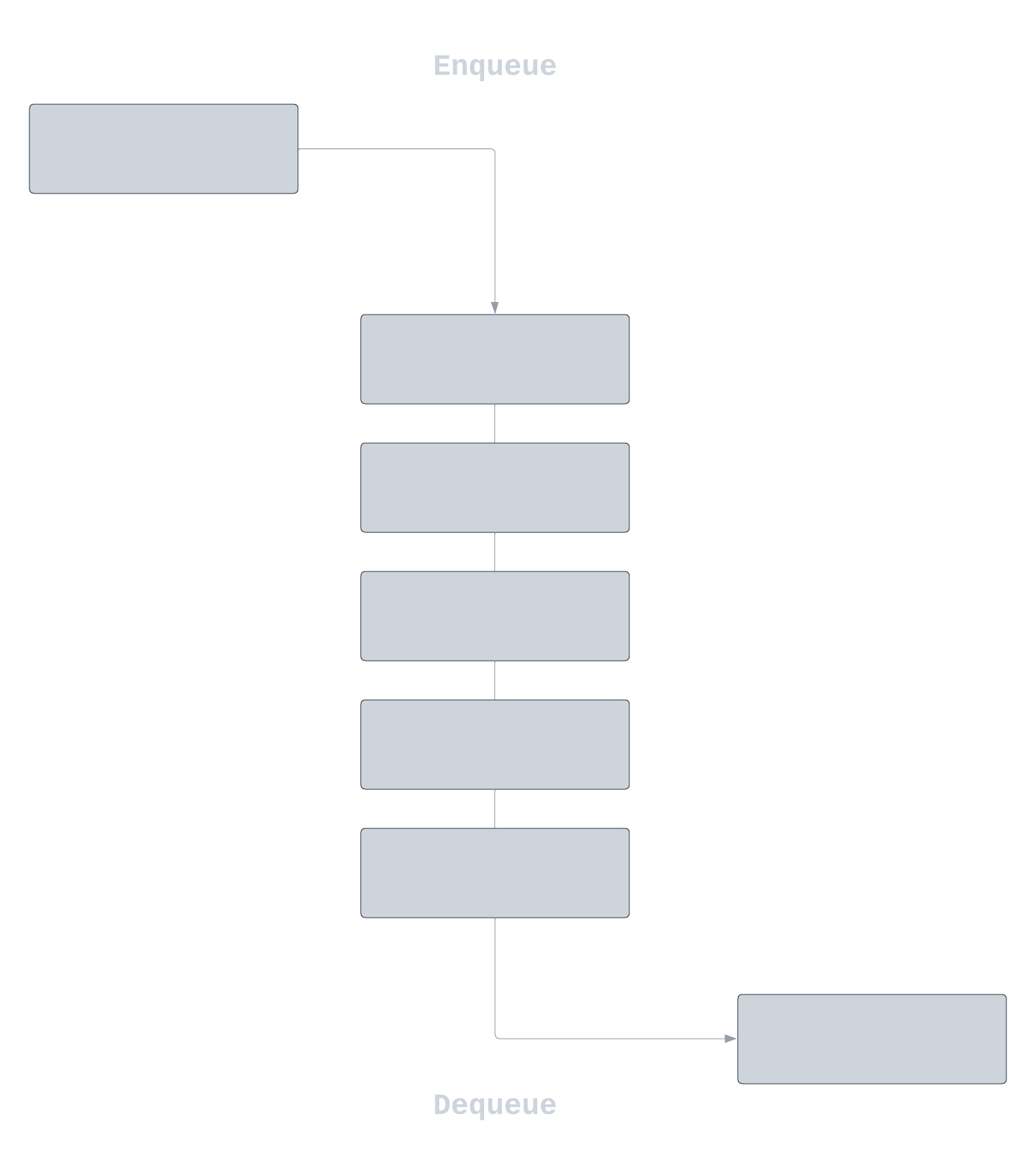
A
ForkJoinPooldiffers from other kinds ofExecutorServicemainly by virtue of employing work-stealing: all threads in the pool attempt to find and execute tasks submitted to the pool and/or created by other active tasks (eventually blocking waiting for work if none exist).
The platform thread to which the scheduler assigns a virtual thread is called the virtual thread carrier. Virtual threads can be scheduled on different carriers over the course of their lifetime. Basically, the scheduler does not maintain affinity between a virtual thread and any kind of platform thread.
The scheduler does not at this time implement time sharing for virtual threads. While time sharing can be an effective way of reducing the latency of certain tasks where it could be that there are a small number of platform threads and CPU utilization is at 100%, it is not clear that it would be as effective with a million virtual threads.
Thread-per-request strategy
To handle concurrent user requests that are independent of each other, server applications generally have been using a thread-pre-request strategy so that it can handle a request dedicated to a thread under its entire duration.
The strategy is easy to understand, easy to implement, debug and profile because it uses the platform's unit of concurrency to represent the application's unit of concurrency.
Unfortunately, the number of available threads are limited because how the JDK implements threads as wrappers around the operating system (OS) threads. They are costly, so using too many of them would make the implementation ill-suited because it's a limiting factor if we want to focus on throughput before we exhaust CPU or network connections.
By using virtual threads this will make this strategy viable since we can now handle much more requests with virtual threads.
Thread pools - why you should not use them with virtual threads
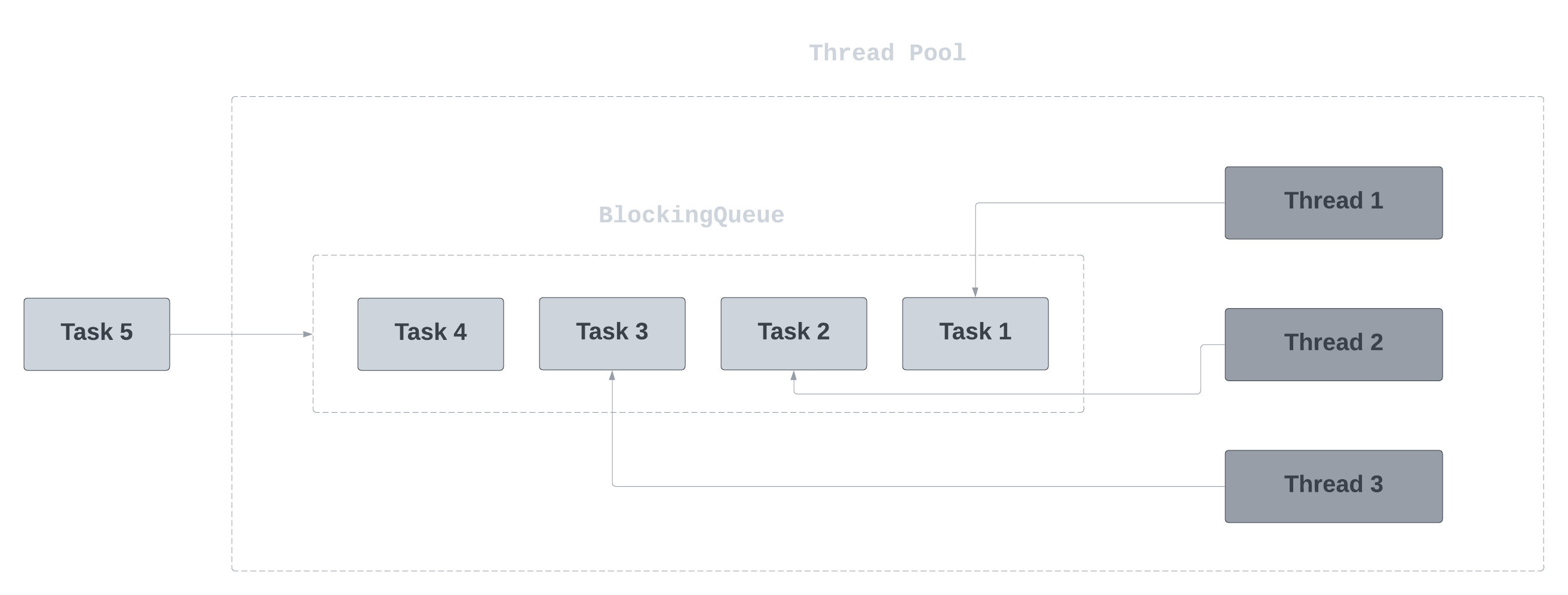
Migrating the application code using the virtual-thread-per-task ExercutorService similar to the traditional thread-pool based ExercutorService is not necessary since there is never a need to pool them. A thread pool is like any other resource pool, intended to share expensive resources, but with virtual threads, they are not expensive.
We typically use thread pools to limit concurrent access to limited resources. Let's say a service cannot handle more than 20 concurrent requests, we typically make all requests to the service via tasks submitted to a thread pool of size 20 and that will fix it. The high cost of platform threads has made thread pools ubiquitous.
Avoid using thread pool for virtual threads!
Memory use and interaction with GC
Java's garbage-collected heap stores the stacks of virtual threads as chunk objects. It will grow and shrink the stacks as the application runs, both to be memory-efficient and to accommodate stacks of depth up to the JVM's configured platform thread stack size.
The amount of activity of the heap space and garbage collector that virtual threads require is hard, specifically when we compare that to asynchronous code. If we would use a million virtual threads, that would be equal to at least a million objects, but so would a million tasks sharing a pool of platform threads.
Thread-local variables
Virtual threads support thread-local variables, ThreadLocal, and inheritable thread-local variables InhertiableThreadLocal. Just like the platform threads, they can run existing code that uses thread locals. Although use thread-locals after careful consideration since virtual threads can be very numerous.
We can use the system property jdk.traceVirtualThreadLocals trigger a stack trace when a virtual thread sets a value of any thread-local variable. With this diagnostic output, it may assist with removing thread-locals if migrating code to use virtual threads. The default value is false.
Summary
So now you probably know a little bit more about Virtual Threads. The tests I conducted could probably be improved, so feel free to contribute to my repo (link below). I will make sure the article is up-to-date and accurate.
The repository used you can find here: https://github.com/mjovanc/java-21-virtual-threads/tree/master
If you found it valuable, please consider sharing it, as it might also be valuable to others. Let me know if you have any questions by reaching me on 𝕏!
Resources
- JDK 21
- JEP 444: Virtual Threads
- Oracle - Virtual Threads
- Class ForkJoinPool
- Thread Pools
- FIFO
- Class Runnable